
The Incident That Made Me Stop Trusting Retries
A few years ago, while working on a fintech product integrating with telecom providers in Ghana (MTN and Vodafone), I ran into a problem that completely changed how I think about retries.
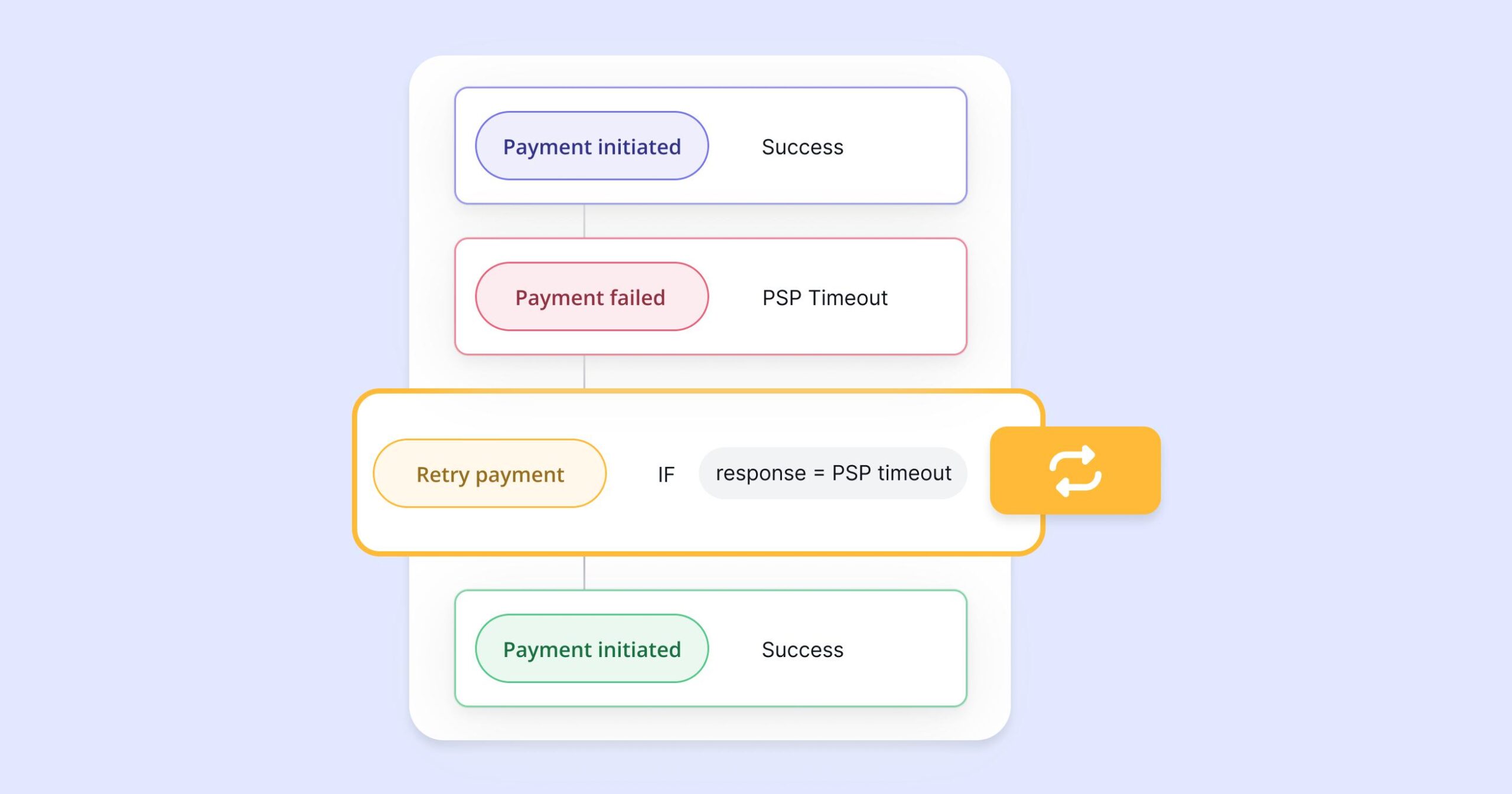
We initiated a payment request.
The API responded with a network error.
The system treated it as a failure and retried the request.
Later, during reconciliation, we discovered that the original transaction had actually gone through. The retry caused a duplicate payment.
That incident forced me to rethink something I had always considered a best practice: retrying failed requests.
The Problem Isn’t Retries — It’s Assumptions
In most backend systems, retries are a good thing. Libraries like Polly make it easy to implement them, and in many scenarios they improve reliability.
But payment systems are different.
Retries assume that a failed response means the operation didn’t complete. In financial systems, that assumption often doesn’t hold.
With external providers—especially in environments with unstable networks—you can get:
- Timeouts after a request has already been processed
- Connection drops before a response is returned
- Inconsistent or delayed status updates
What you end up with is not a failure, but an unknown outcome.
And if you retry in that state, you risk executing the same financial operation twice.
Timeout Does Not Mean Failure
One of the most important mindset shifts for me was this:
A timeout is not a failure. It simply means you don’t know what happened.
That distinction matters.
If you treat timeouts as failures, retries feel safe.
If you treat them as unknowns, retries become risky.
Where Retries Become Dangerous
Retries are particularly risky when:
- The operation is not idempotent
- The provider does not support idempotency
- There is no reliable way to check transaction status immediately
- The system operates in unreliable network conditions
This combination is common in real-world fintech integrations, especially when dealing with telcos or legacy systems.
In these cases, retries don’t improve reliability—they increase the chance of financial inconsistencies.
What I Do Instead
Over time, I’ve moved toward patterns that prioritize correctness over blind resilience.
Idempotency First
Every transaction should have a unique identifier.
If the same request is sent twice, the provider should recognize it and return the original result instead of processing it again.
If the provider doesn’t support idempotency, you need to enforce it on your side as much as possible.
Reconcile Before You Retry
When a request fails:
- Mark the transaction as pending or unknown
- Query the provider’s status endpoint
- Only retry if you can confirm that the transaction was not processed
This adds latency, but it prevents duplicate financial operations.
Treat External Calls as Asynchronous
Instead of tightly coupling request and response:
- Persist the outgoing request
- Process it through a controlled workflow
- Track its state explicitly
This gives you visibility and control, especially when things go wrong.
Plan for Compensation
Even with the best design, edge cases will happen.
You need mechanisms to:
- Reverse transactions
- Issue refunds
- Handle reconciliation discrepancies
In fintech, recovery paths are just as important as happy paths.
When Retries Are Actually Fine
To be clear, retries are not inherently bad.
They work well for:
- Idempotent operations
- Internal service communication
- Non-financial workflows
The problem is applying the same pattern to payment initiation without considering the risks.
Polly Isn’t the Problem
Libraries like Polly are extremely useful. The issue isn’t the tool—it’s how and where it’s used.
Retries are a technical solution. Payment processing is a domain problem.
If you ignore the domain constraints, even good tools can lead to bad outcomes.
Final Thoughts
In financial systems, correctness matters more than availability.
A failed request can be retried later.
A duplicated transaction is much harder to fix.
The goal is not to avoid retries entirely, but to use them with a clear understanding of the risks.
For me, the rule is simple:
Retries are acceptable when the outcome is known.
They are dangerous when the outcome is uncertain.
And in payment systems, uncertainty is more common than most people expect.